在當今大數據時代,億級數據的聚合處理已成為許多企業和組織的核心需求。傳統的數據處理方法在面對海量數據時往往效率低下,甚至無法完成任務。因此,開發一種高效、可擴展的億級聚合數據處理方法至關重要。
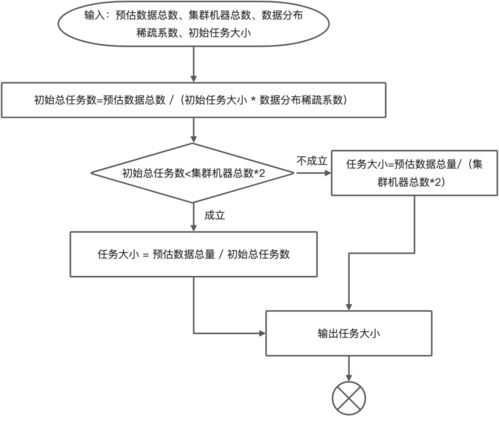
數據分片是處理億級聚合數據的基礎。通過將數據劃分為多個較小的片段,可以并行處理這些片段,顯著提高處理速度。例如,可以使用哈希分片或范圍分片策略,將數據均勻分布到多個計算節點上。這種方法不僅減少了單個節點的負載,還充分利用了分布式系統的計算能力。
采用分布式計算框架是實現高效聚合的關鍵。Apache Spark、Flink等現代計算框架提供了強大的聚合功能,支持內存計算和容錯機制。以Spark為例,其RDD(彈性分布式數據集)和DataFrame API可以輕松實現分組、求和、計數等聚合操作,并通過優化執行計劃提升性能。對于億級數據,Spark的分布式聚合能夠將任務分解為多個階段,并在集群中并行執行,大大縮短處理時間。
數據預處理和索引優化也是不可忽視的環節。在聚合之前,對數據進行清洗、去重和壓縮,可以減少不必要的計算開銷。同時,為常用聚合字段建立索引,如使用布隆過濾器或B樹索引,可以加速數據查找和聚合過程。例如,在時間序列數據聚合中,按時間戳建立索引可以快速定位特定時間范圍的數據,提升聚合效率。
資源管理和監控是確保系統穩定運行的重要保障。通過動態資源分配和負載均衡,系統可以根據數據量和計算需求自動調整資源使用。監控工具如Prometheus或Grafana可以幫助實時跟蹤聚合任務的進度和性能指標,及時發現并解決瓶頸問題。
通過數據分片、分布式計算框架、數據預處理與索引優化以及資源管理監控,我們可以構建一種高效處理億級聚合數據的方法。這種方法不僅提升了數據處理速度,還保證了系統的可擴展性和穩定性,適用于電商、金融、物聯網等多個領域的大數據應用場景。