在大數(shù)據(jù)時代,處理海量數(shù)據(jù)已成為企業(yè)運營與決策的核心需求。尤其是在互聯(lián)網(wǎng)技術(shù)領(lǐng)域,無論是用戶行為分析、日志處理,還是推薦系統(tǒng)優(yōu)化,都需要對TB甚至PB級別的數(shù)據(jù)進行高效、準(zhǔn)確的排序。Hadoop作為分布式計算框架的基石,為大規(guī)模數(shù)據(jù)的全局排序提供了強大的技術(shù)支持。
一、Hadoop排序的核心機制
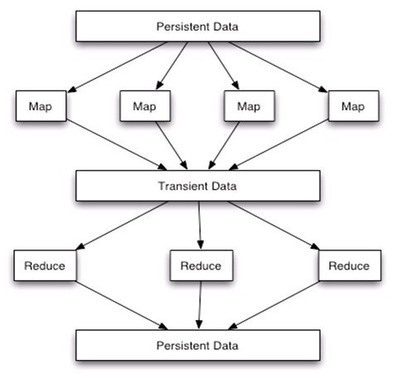
Hadoop的MapReduce編程模型天然支持排序。在Shuffle階段,Map任務(wù)輸出的中間結(jié)果會按照Key進行分區(qū)和排序,然后發(fā)送給Reduce任務(wù)。Reduce任務(wù)在接收數(shù)據(jù)時,也會對來自不同Map任務(wù)的相同Key的數(shù)據(jù)進行歸并排序。這種機制使得在單個Reduce任務(wù)中,數(shù)據(jù)是全局有序的。
要實現(xiàn)真正意義上的全局排序(即所有數(shù)據(jù)按照一個全局順序排列),通常需要一個Reduce任務(wù)。當(dāng)數(shù)據(jù)量極大時,單Reduce任務(wù)會成為性能瓶頸。因此,實際應(yīng)用中常采用“抽樣-范圍分區(qū)”的策略:
- 抽樣階段:運行一個抽樣作業(yè),從數(shù)據(jù)集中抽取少量Key樣本。
- 生成分區(qū)文件:對樣本進行排序,并根據(jù)樣本的分布情況,計算出一個分區(qū)邊界列表,確保每個分區(qū)包含大致相等的數(shù)據(jù)量。
- 全局排序作業(yè):在正式的排序作業(yè)中,使用
TotalOrderPartitioner,并加載上一步生成的分區(qū)文件。這樣,Map任務(wù)輸出的數(shù)據(jù)會根據(jù)Key所屬的范圍被分發(fā)到不同的Reduce任務(wù),每個Reduce任務(wù)處理一個范圍的數(shù)據(jù),并在內(nèi)部進行排序。所有Reduce任務(wù)的輸出按分區(qū)順序拼接起來,就是全局有序的結(jié)果。
二、關(guān)鍵技術(shù)實現(xiàn)與優(yōu)化
1. 自定義Key與Comparator
為了實現(xiàn)復(fù)雜排序邏輯(如二次排序),需要自定義WritableComparable的Key類,并實現(xiàn)compareTo方法。可能需要為Map端排序、Reduce端分組和Reduce端排序分別設(shè)置不同的Comparator。
2. 使用Combiner減少數(shù)據(jù)傳輸
在Map端使用Combiner進行本地聚合,可以顯著減少Shuffle階段需要傳輸?shù)臄?shù)據(jù)量,提升整體性能。但需注意,Combiner的操作必須是冪等的,且不影響最終結(jié)果。
3. 內(nèi)存與磁盤優(yōu)化
調(diào)整io.sort.mb(Map端排序緩沖區(qū)大小)、io.sort.factor(歸并因子)等參數(shù),可以在內(nèi)存使用和磁盤I/O之間找到最佳平衡點,防止作業(yè)因內(nèi)存溢出而失敗。
4. 并行度調(diào)優(yōu)
合理設(shè)置Reduce任務(wù)的數(shù)量至關(guān)重要。數(shù)量太少會導(dǎo)致單個任務(wù)負載過重,太多則會增加任務(wù)啟動和調(diào)度的開銷。通常,Reduce任務(wù)數(shù)可設(shè)置為集群中可用Reduce槽位的0.95到1.75倍。
三、在互聯(lián)網(wǎng)技術(shù)與電腦動畫設(shè)計中的應(yīng)用
互聯(lián)網(wǎng)技術(shù)領(lǐng)域
- 用戶畫像與行為分析:對數(shù)十億用戶的點擊流、購買記錄按時間或權(quán)重排序,進行趨勢分析和用戶分群。
- 搜索引擎索引構(gòu)建:對全網(wǎng)爬取的海量網(wǎng)頁數(shù)據(jù),按PageRank、關(guān)鍵詞相關(guān)性等指標(biāo)進行排序,生成倒排索引。
- 廣告點擊率(CTR)預(yù)估:對海量的廣告曝光、點擊日志按用戶、廣告位等進行排序,用于模型訓(xùn)練和效果評估。
電腦動畫設(shè)計領(lǐng)域
隨著3D動畫、特效渲染的數(shù)據(jù)量激增,Hadoop排序也能發(fā)揮作用:
- 渲染任務(wù)調(diào)度:對成千上萬的渲染幀任務(wù),根據(jù)復(fù)雜度、依賴關(guān)系、優(yōu)先級進行全局排序,優(yōu)化渲染農(nóng)場的任務(wù)隊列,提高整體渲染效率。
- 資產(chǎn)管理與版本控制:對龐大的模型、紋理、動畫序列文件,按修改時間、文件大小或項目依賴進行排序,便于團隊協(xié)作和資產(chǎn)管理。
- 動作捕捉數(shù)據(jù)處理:對連續(xù)的動作捕捉數(shù)據(jù)流(如MoCap數(shù)據(jù)),按時間戳進行全局排序和清洗,為后續(xù)的動畫合成提供準(zhǔn)備。
四、實踐注意事項
- 數(shù)據(jù)傾斜問題:如果某個Key的數(shù)據(jù)量異常龐大,會導(dǎo)致對應(yīng)的Reduce任務(wù)執(zhí)行緩慢,成為“拖后腿”的任務(wù)。需要通過更好的抽樣策略或自定義分區(qū)邏輯來緩解。
- 容錯與監(jiān)控:Hadoop作業(yè)運行時間可能很長,需關(guān)注作業(yè)進度、資源使用情況,并處理好可能的失敗重試。
- 輸出格式:排序后的輸出通常選擇順序文件格式(SequenceFile),它能更好地支持大數(shù)據(jù)塊和壓縮,便于后續(xù)處理。
###
利用Hadoop進行大規(guī)模數(shù)據(jù)的全局排序,是一項將分布式計算理論付諸實踐的關(guān)鍵技術(shù)。通過深入理解MapReduce的排序機制,并結(jié)合巧妙的抽樣分區(qū)策略,我們能夠高效地駕馭海量數(shù)據(jù),為互聯(lián)網(wǎng)服務(wù)和數(shù)字內(nèi)容創(chuàng)作(如電腦動畫設(shè)計)提供深度的數(shù)據(jù)洞察和強大的處理能力。隨著計算框架的演進(如Spark在某些場景下提供了更優(yōu)的排序性能),其核心思想——分而治之、抽樣與范圍分區(qū)——依然是處理超大規(guī)模數(shù)據(jù)排序的寶貴財富。